第 10 章:透過集群聯邦管理集群
為什麽要使用集群聯邦(Cluster Federation)
Federation 使管理多個集群變得簡單。它通過提供兩個主要構建模塊來實現:
- 跨集群同步資源:Federation 提供了在多個集群中保持資源同步的能力。例如,可以保證同一個 deployment 在多個集群中存在。
- 跨集群服務發現:Federation 提供了自動配置 DNS 服務以及在所有集群後端上進行負載均衡的能力。例如,可以提供一個全局 VIP 或者 DNS 記錄,通過它可以訪問多個集群後端。 Federation 還可以提供一些其它用例:
- 高可用:通過在集群間分布負載並自動配置 DNS 服務和負載均衡,federation 最大限度地減少集群故障的影響。
- 避免廠商鎖定:通過更簡單的跨集群應用遷移方式,federation 可以防止集群廠商鎖定。 Federation 對於單個集群沒有用處。基於下面這些原因你可能會需要多個集群:
- 低延遲:通過在多個區域部署集群可以最大限度減少區域近端用戶的延遲。
- 故障隔離:擁有多個小集群可能比單個大集群更利於故障隔離(例如:在雲服務提供商的不同可用區中的多個集群)。
- 可伸縮性:單個集群有可伸縮性限制(對於大多數用戶這不是典型場景。更多細節請參考 Kubernetes 彈性伸縮與性能目標)。 混合��雲:你可以在不同的雲服務提供商或本地數據中心中擁有多個集群。
警告
- 增加網絡帶寬和成本:federation 控制平面監控所有集群以確保當前狀態符合預期。如果集群在雲服務提供商的不同區域或者不同的雲服務提供商上運行時,這將導致明顯的網絡成本增加。
- 減少跨集群隔離:federation 控制平面中的 bug 可能影響所有集群。通過在 federation 中實現最少的邏輯可以緩解這種情況。只要有可能,它就將盡力把工作委托給 kubernetes 集群中的控制平面。這種設計和實現在安全性及避免多集群停止運行上也是錯誤的。
- 成熟度:federation 項目相對比較新,還不是很成熟。並不是所有資源都可用,許多仍然處於 alpha 狀態。 Issue 88 列舉了團隊目前正忙於解決的與系統相關的已知問題。
混合雲能力
- Kubernetes 集群 federation 可以包含運行在不同雲服務提供商(例如 Google Cloud、AWS)及本地(例如在 OpenStack 上)的集群。你只需要按需在適合的雲服務提供商和 / 或地點上簡單的創建集群,然後向 Federation API Server 注冊每個集群的 API endpoint 和憑據即可。
此後,你的 API 資源就可以跨越不同的集群和雲服務提供商。
單個集群範圍
在諸如 Google Compute Engine 或者 Amazon Web Services 等 IaaS 服務提供商中,虛擬機存在於 區域(Zone) 或 可用區(Availability Zone) 上。我們建議 Kubernetes 集群中的所有虛擬機應該位於相同的可用區,因為:
與擁有單個全局 Kubernetes 集群相比,單點故障更少。 與跨可用區集群相比,推測單區域集群的可用性屬性更容易。 當 Kubernetes 開發人員設計系統時(例如對延遲,帶寬或相關故障進行假設),它們假設所有的機器都在一個單一的數據中心,或以其它方式緊密連接。 在每個可用區域同時擁有多個集群也是可以的,但總體而言,我們認為少一點更好。選擇較少集群的理由是:
某些情況下,在一個集群中擁有更多的節點可以改進 Pod 的裝箱打包(較少資源碎片)。 減少運維開銷(盡管隨著運維工具和流程的成熟,優勢已經減少)。 減少每個集群固定資源成本的開銷,例如 apiserver 虛擬機(但對於大中型集群的整體集群成本來說百分比很小)。 擁有多個集群的原因包括:
嚴格的安全策略要求將一類工作與另一類工作隔離開來(但是,請參見下面的分區集群(Partitioning Clusters))。 對新的 Kubernetes 發行版或其它集群軟件進行灰度測試。
選擇正確的集群數量
Kubernetes 集群數量的選擇可能是一個相對靜態的選擇,只是偶爾重新設置。相比之下,依據負載情況和增長,集群的節點數量和 service 的 pod 數量可能會經常變化。
要選擇集群的數量,首先要確定使用哪些區域,以便為所有終端用戶提供足夠低的延遲,以在 Kubernetes 上運行服務,如果你使用內容分發網絡(Content Distribution Network,CDN),則 CDN 托管內容的時延要求不需要考慮。法律問題也可能影響到這一點。例如,擁有全球客戶群的公司可能會決定在美國、歐盟、亞太和南亞地區擁有集群。我們將選擇的區域數量稱為 R。
其次,決定在整體仍然可用的前提下,可以同時有多少集群不可用。將不可用集群的數量稱為 U。如果你不能確定,那麽 1 是一個不錯的選擇。
如果在集群故障的情形下允許負載均衡將流量引導到任何區域,則至少需要有比 R 或 U + 1 數量更大的集群。如果不行的話(例如希望在集群發生故障時對所有用戶確保低延遲),那麽你需要有數量為 R * (U + 1) 的集群(R 個區域,每個中有 U + 1 個集群)。無論如何,請嘗試將每個集群放在不同的區域中。
最後,如果你的任何集群需要比 Kubernetes 集群最大建議節點數更多的節點,那麽你可能需要更多的集群。Kubernetes v1.3 支持最多 1000 個節點的集群。Kubernetes v1.8 支持最多 5000 個節點的集群。
Kubernetes 集群聯邦的演進
Kubernetes 官方博客的文章中介紹了 Kubernetes 集群聯邦的演進,該項目是在 SIG Multicluster 中進行的,Federation 是 Kubernetes 的一個子項目,社區對這個項目的興趣很濃,該項目最初重用 Kubernetes API,以消除現有 Kubernetes 用戶的任何附加使用覆雜性。但由於以下原因,此方式行不通:
在集群層面重新實施 Kubernetes API 的困難,因為 Federation 的特定擴展存儲在注釋中。 由於 Kubernetes API 的 1:1 仿真,Federation 類型、放置(placement)和調節(reconciliation)的靈活性有限。 沒有固定的 GA 路徑,API 成熟度普遍混亂;例如,Deployment 在 Kubernetes 中是 GA,但在 Federation v1 中甚至不是 Beta。 隨著 Federation 特定的 API 架構和社區的努力,這些想法有了進一步的發展,改進為 Federation v2。請注意,Federation V1 版本已經歸檔不再維護和更新,且官方也不再推薦繼續使用。如果需要了解更多的 Federation 資料,請參考:Kubernetes Federation v2。
下面將帶你了解 Federation v2 背後的考量。
將任意資源聯合起來
聯邦的主要目標之一是能夠定義 API 和 API 組,其中包含聯邦任何給定 Kubernetes 資源所需的基本原則。這是至關重要的,因為 CRD 已經成為擴展 Kubernetes API 的一種主流方式。
Multicluster SIG 得出了 Federation API 和 API 組的共同定義,即 “一種將規範的 Kubernetes API 資源分配到不同集群的機制”。最簡單的分布形式可以想象為這種’規範的 Kubernetes API 資源’在聯邦集群中的簡單傳播。除了這種簡單的 Kubernetes 資源傳播之外,有心的讀者當然可以看出更覆雜的機制。
在定義 Federation API 的構建模塊的歷程中,最早期的目標也演化為 “能夠創建一個簡單的聯邦,也就是任何 Kubernetes 資源或 CRD 的簡單傳播,幾乎不需要編寫代碼”。隨後,核心 API 組進一步定義了構件,即每個給定的 Kubernetes 資源有一個 Template 資源、一個 Placement 資源和一個 Override 資源,一個 TypeConfig 來指定給定資源的同步或不同步,以及執行同步的相關控制器。更多細節將在後文中介紹��。進一步的章節還將談到能夠遵循分層行為,更高級別的 Federation API 消耗這些核心構件的行為,而用戶能夠消耗整個或部分 API 和相關控制器。最後,這種架構還允許用戶編寫額外的控制器或用自己的控制器替換現有的參考控制器(reference controller),以執行所需的行為。
能夠 “輕松地聯合任意 Kubernetes 資源”,以及一個解耦的 API,分為構件 API、更高層次的 API 和可能的用戶預期類型,這樣的呈現方式使得不同的用戶可以消費部分和編寫控制器組成特定的解決方案,這為 Federation v2 提供了一個令人信服的案例。
聯邦服務與跨集群服務發現
Kubernetes 服務在構建微服務架構時非常有用。人們明顯希望跨越集群、可用區、區域和雲的邊界來部署服務。跨集群的服務提供了地理分布,實現了混合和多雲場景,並提高了超越單一集群部署的高可用性水平。希望其服務跨越一個或多個(可能是遠程)集群的客戶,需要在集群內外以一致的方式提供服務。
Federated Service 的核心是包含一個 Template(Kubernetes 服務的定義)、一個 Placement(部署到哪個集群)、一個 Override(在特定集群中的可選變化)和一個 ServiceDNSRecord(指定如何發現它的細節)。
注意:聯邦服務必須是 LoadBalancer 類型,以便它可以跨集群發現。
Pod 如何發現聯邦服務
默認情況下,Kubernetes 集群預先配置了集群本地 DNS 服務器,以及智能構建的 DNS 搜索路徑,它們共同確保了由 pod 內部運行的軟件發出的 myservice、myservice.mynamespace 或 some-other-service.other-namespace 等 DNS 查詢會自動擴展並正確解析到本地集群中運行的服務的相應 IP。
隨著聯邦服務和跨集群服務發現的引入,這個概念被擴展到全局覆蓋在你的集群聯邦中所有集群中運行的 Kubernetes 服務。為了利用這個擴展的範圍,我們需要使用一個稍微不同的 DNS 名稱(例如 myservice.mynamespace.myfederation)來解析聯邦服務。使用不同的 DNS 名還可以避免現有的應用意外地穿越區域網絡而會產生不必要的網絡費用或延遲。
讓我們看一個例子,使用一個名為 nginx 的服務。
在 us-central1-a 可用區的集群中的一個 pod 需要聯系我們的 nginx 服務。它現在可以使用服務的聯邦 DNS 名,即 nginx.mynamespace.myfederation ,而不是使用服務的傳統集群本地 DNS 名(即 nginx.mynamespace 自動擴展為 nginx.mynamespace.svc.cluster.local)。這將被自動擴展並解析到離我的 nginx 服務最近的健康 shard。如果本地集群中存在一個健康的 shard,那麽該服務的集群本地 IP 地址將被返回(通過集群本地 DNS)。這完全等同於非聯邦服務解析。
如果服務在本地集群中不存在(或者存在但沒有健康的後端 pod),DNS 查詢會自動擴展到 nginx.mynamespace.myfederation.svc.us-central1-a.example.com。在幕後,這可以找到離我們的可用區最近的一個 shard 的外部 IP。這個擴展是由集群本地 DNS 服務器自動執行的,它返回相關的 CNAME 記錄。這就導致了對 DNS 記錄的層次結構的遍歷,並最終找到附近聯邦服務的一個外部 IP。
也可以通過明確指定適當的 DNS 名稱,而不是依賴自動的 DNS 擴展,將目標鎖定在 pod 本地以外的可用性區域和地區的服務 shard。例如,nginx.mynamespace.myfederation.svc.europe-west1.example.com 將解析到歐洲所有當前健康的服務 shard,即使發布查詢的 pod 位於美國,也不管美國是否有健康的服務 shard,這對遠程監控和其他類似的應用很有用。
從聯邦集群之外的其他客戶端發現聯邦服務
對於外部客戶端,目前還不能實現所述自動 DNS 擴展。外部客戶需要指定聯邦服務的一個完全限定的 DNS 名稱,無論是區域、可用區還是全局名稱。為了方便起見,通常情況下,在服務中手動配置額外的靜態 CNAME 記錄是一個好主意,例如:
| 短名稱 | CNAME |
|---|---|
| eu.nginx.acme.com | nginx.mynamespace.myfederation.svc.europe-west1.example.com |
| us.nginx.acme.com | nginx.mynamespace.myfederation.svc.us-central1.example.com |
| nginx.acme.com | nginx.mynamespace.myfederation.svc.example.com |
這樣一來,你的客戶就可以始終使用左邊的短名稱,並始終自動路由到離他們位置最近的健康 shard。所有所需的故障轉移都由 Kubernetes 集群聯邦為你自動處理。
架構概覽
Kubernetes Cluster Federation 又名 KubeFed 或 Federation v2,v2 架構在 Federation v1 基礎之上��,簡化擴展 Federated API 過程,並加強跨集群服務發現與編排的功能。另外 KubeFed 在設計之初,有兩個最重要核心理念是 KubeFed 希望實現的,分別為 Modularization(模塊化)與 Customizable (定制化),這兩個理念大概是希望 KubeFed 能夠跟隨著 Kubernetes 生態發展,並持續保持相容性與擴展性。
由於 Federation 試圖解決一系列覆雜的問題,因此需要將這些問題的不同部分分解開來。Federation 中涉及的概念和架構圖如下所示。
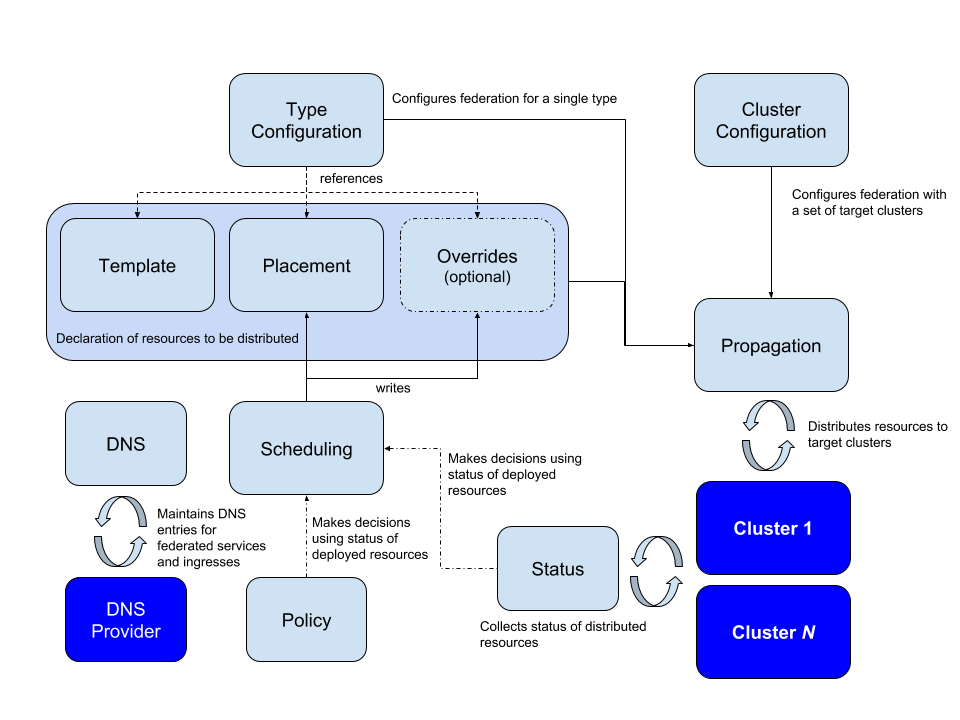
配置需要聯邦的集群 配置需要在集群中傳播的 API 資源 配置 API 資源如何分配到不同的集群 對集群中 DNS 記錄注冊 相較於 v1,v2 在組件上最大改變是將 API Server 移除,並通過 CRD 機制來完成 Federated Resources 的擴充。而 KubeFed Controller 則管理這些 CRD,並實現同步資源、跨集群編排等功能。
目前 KubeFed 通過 CRD 方式新增了四種 API 群組來實現聯邦機制的核心功能:
| API Group | 用途 |
|---|---|
| core.kubefed.k8s.io | 集群組態、聯邦資源組態、KubeFed Controller 設定檔等。 |
| types.kubefed.k8s.io | 被聯邦的 Kubernetes API 資源。 |
| scheduling.kubefed.k8s.io | 副本編排策略。 |
| multiclusterdns.kubefed.k8s.io | 跨集群服務發現設定。 |
在這些核心功能中,我們必須先了解一些 KebeFed 提出的基礎概念後,才能更清楚知道 KubeFed 是如何運作的。
Cluster Configuration
用來定義哪些 Kubernetes 集群要被聯邦。可通過 kubefedctl join/unjoin 來加入/刪除集群,當成功加入時,會建立一個 KubeFedCluster 組件來儲存集群相關信息,如 API Endpoint、CA Bundle 等。這些信息會被用在 KubeFed Controller 存取不同 Kubernetes 集群上,以確保能夠建立 Kubernetes API 資源,示意圖如下所示。
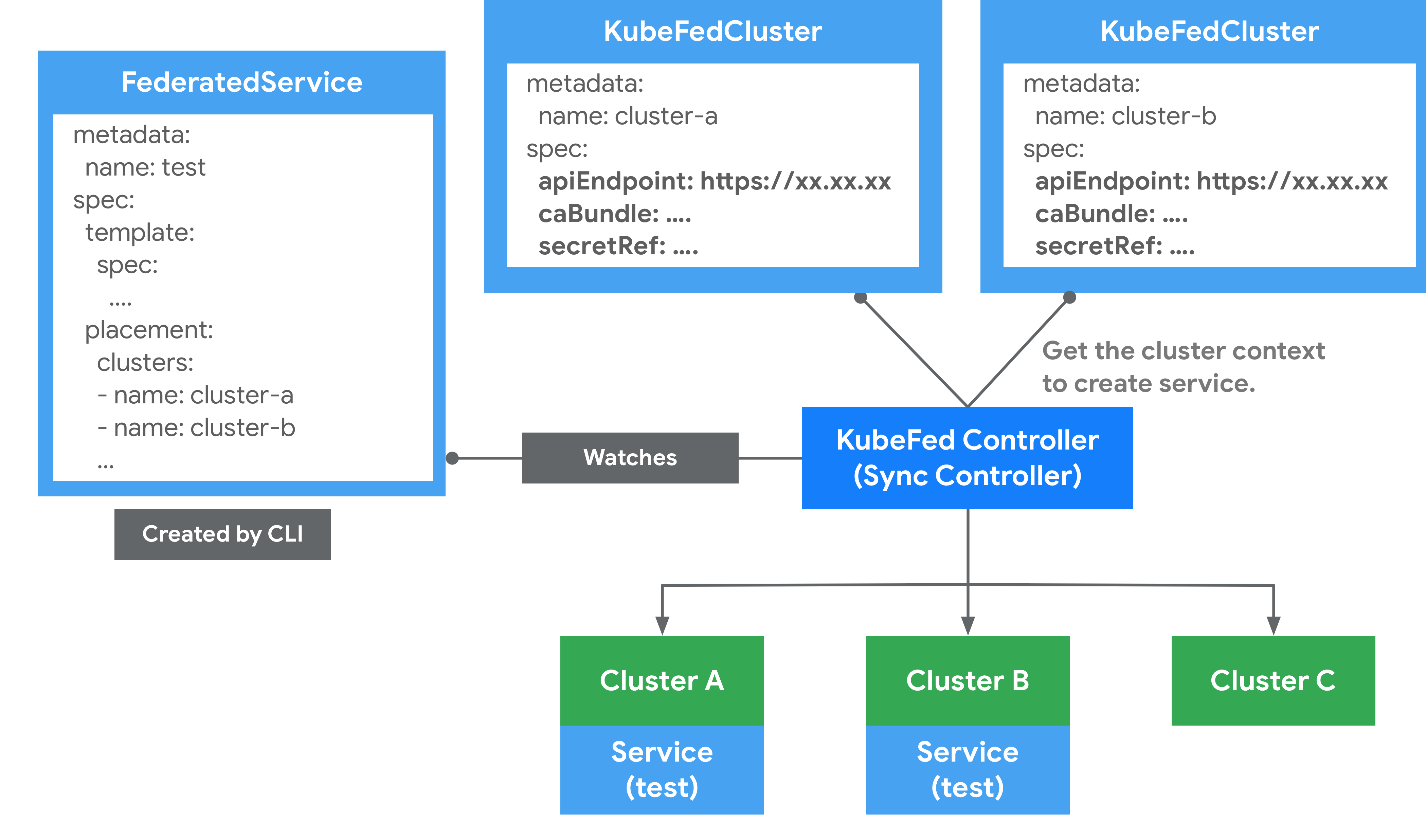
在 Federation 中,會區分 Host 與 Member 兩種類型集群。
Host : 用於提供 KubeFed API 與控制平面的集群。 Member : 通過 KubeFed API 注冊的集群,並提供相關身份憑證來讓 KubeFed Controller 能夠存取集群。Host 集群也可以作為 Member 被加入。
Type Configuration
定義了哪些 Kubernetes API 資源要被用於聯邦管理。比如說想將 ConfigMap 資源通過聯邦機制建立在不同集群上時,就必須先在 Federation Host 集群中,通過 CRD 建立新資源 FederatedConfigMap,接著再建立名稱為 configmaps 的 Type configuration(FederatedTypeConfig)資源,然後描述 ConfigMap 要被 FederatedConfigMap 所管理,這樣 KubeFed Controllers 才能知道如何建立 Federated 資源。以下為簡單範例:
apiVersion: core.kubefed.k8s.io/v1beta1
kind: FederatedTypeConfig
metadata:
name: configmaps
namespace: kube-federation-system
spec:
federatedType:
group: types.kubefed.k8s.io
kind: FederatedConfigMap
pluralName: federatedconfigmaps
scope: Namespaced
version: v1beta1
propagation: Enabled
targetType:
kind: ConfigMap
pluralName: configmaps
scope: Namespaced
version: v1
若想新增 CRD 的 Federated API 的話,可通過 kubefedctl enable <res> 指令來建立,如下:
kubefedctl enable etcdclusters
kubectl api-resources | grep etcd
etcdclusters etcd etcd.database.coreos.com true EtcdCluster
federatedetcdclusters fetcd types.kubefed.k8s.io true FederatedEtcdCluster
kubectl -n kube-federation-system get federatedtypeconfigs | grep etcd
etcdclusters.etcd.database.coreos.com 3m16s
而一個 Federated 資源一般都會具備三個主要功能,這些信息能夠在 spec 中由使用者自行定義,如下範例:
apiVersion: types.kubefed.k8s.io/v1beta1
kind: FederatedDeployment
metadata:
name: test-deployment
namespace: test-namespace
spec:
template: # 定義 Deployment 的所有內容,可理解成 Deployment 與 Pod 之間的關聯。
metadata:
labels:
app: nginx
spec:
...
placement:
clusters:
- name: cluster2
- name: cluster1
overrides:
- clusterName: cluster2
clusterOverrides:
- path: spec.replicas
value: 5
Placement:定義 Federated 資源要分散到哪些集群上,若沒有該文件,則不會分��散到任何集群中。如 FederatedDeployment 中的 spec.placement 定義了兩個集群時,這些集群將被同步建立相同的 Deployment。另外也支持用 spec.placement.clusterSelector 的方式來選擇要放置的集群。 Override:定義修改指定集群的 Federated 資源中的 spec.template 內容。如部署 FederatedDeployment 到不同公有雲上的集群時,就能通過 spec.overrides 來調整 Volume 或副本數。 注意:目前 Override 不支持 List(Array)。比如說無法修改 spec.template.spec.containers [0].image。
Scheduling
KubeFed 提供了一種自動化機制來將工作負載實例分散到不同的集群中,這能夠基於總副本數與集群的定義策略來將 Deployment 或 ReplicaSet 資源進行編排。編排策略是通過建立 ReplicaSchedulingPreference(RSP)文件,再由 KubeFed RSP Controller 監聽與擷取 RSP 內容來將工作負載實例建立到指定的集群上。這是基於用戶給出的高級用戶偏好。這些偏好包括加權分布的語義和分布副本的限制(最小和最大)。這些還包括允許動態重新分配副本的語義,以防某些副本 Pod 仍然沒有被調度到某些集群上,例如由於該集群資源不足。更多細節可以在 ReplicaSchedulingPreferences 的用戶指南中找到。
以下為一個 RSP 範例。假設有三個集群被聯邦,名稱分別為 ap-northeast、us-east 與 us-west。
apiVersion: scheduling.kubefed.k8s.io/v1alpha1
kind: ReplicaSchedulingPreference
metadata:
name: test-deployment
namespace: test-ns
spec:
targetKind: FederatedDeployment
totalReplicas: 15
clusters:
"*":
weight: 2
maxReplicas: 12
ap-northeast:
minReplicas: 1
maxReplicas: 3
weight: 1
該配置示意圖如下所示。
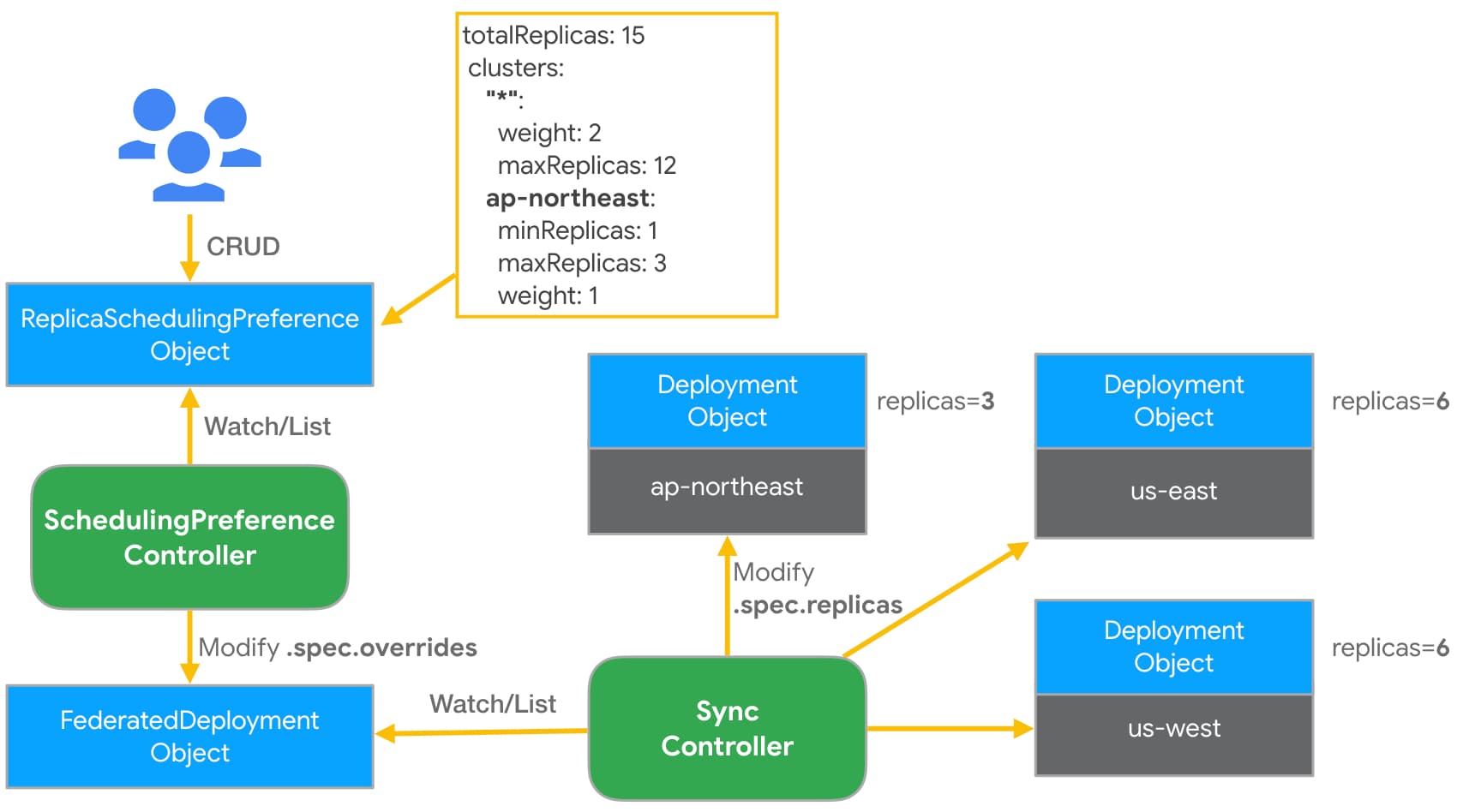
當該範例建立後,RSP Controller 會收到資源,並匹配對應 namespace/name 的 FederatedDeployment 與 FederatedReplicaSet 是否存在,若存在的話,會根據設定的策略計算出每個集群預期的副本數,之後覆寫 Federated 資源中的 spec.overrides 內容以修改每個集群的副本數,最後再由 KubeFed Sync Controller 來同步至每個集群的 Deployment。以上面為例,結果會是 ap-northeast 集群會擁有 3 個 Pod,us-east 跟 us-west 則分別會有 6 個 Pod。
注意:
若 spec.clusters 未定義的話,則預設為 {“*”:{Weight: 1}}。
若有定義 spec.replicas 的 overrides 時,副本會以 RSP 為優先考量。
分配的計算機制可以參考 kubefed/pkg/controller/util/planner/planner.go。
Multi-cluster DNS
KubeFed 提供了一組 API 資源,以及 Controllers 來實現跨集群 Service/Ingress 的 DNS records 自動產生機制,並結合 ExternalDNS 來同步更新至 DNS 服務供應商。以下為簡單例子:
apiVersion: multiclusterdns.kubefed.k8s.io/v1alpha1
kind: Domain
metadata:
name: test
namespace: kube-federation-system
domain: k8s.example.com
---
apiVersion: multiclusterdns.kubefed.k8s.io/v1alpha1
kind: ServiceDNSRecord
metadata:
name: nginx
namespace: development
spec:
domainRef: test
recordTTL: 300
首先假設已建立一個名稱為 nginx 的 FederatedDeployment,然後放到 development namespace 中,並且也建立了對應的 FederatedService 提供 LoadBalancer。這時當建立上述 Domain 與 ServiceDNSRecord 後,KubeFed 的 Service DNS Controller 會依據 ServiceDNSRecord 文件內容,去收集不同集群的 Service 信息,並將這些信息更新至 ServiceDNSRecord 狀態中,接著 DNS Endpoint Controller 會依據該 ServiceDNSRecord 的狀態內容,建立一個 DNSEndpoint 文件,並產生 DNS records 資源,最後再由 ExternalDNS 來同步更新 DNS records 至 DNS 供應商。下圖是 Service DNS 建立的架構。
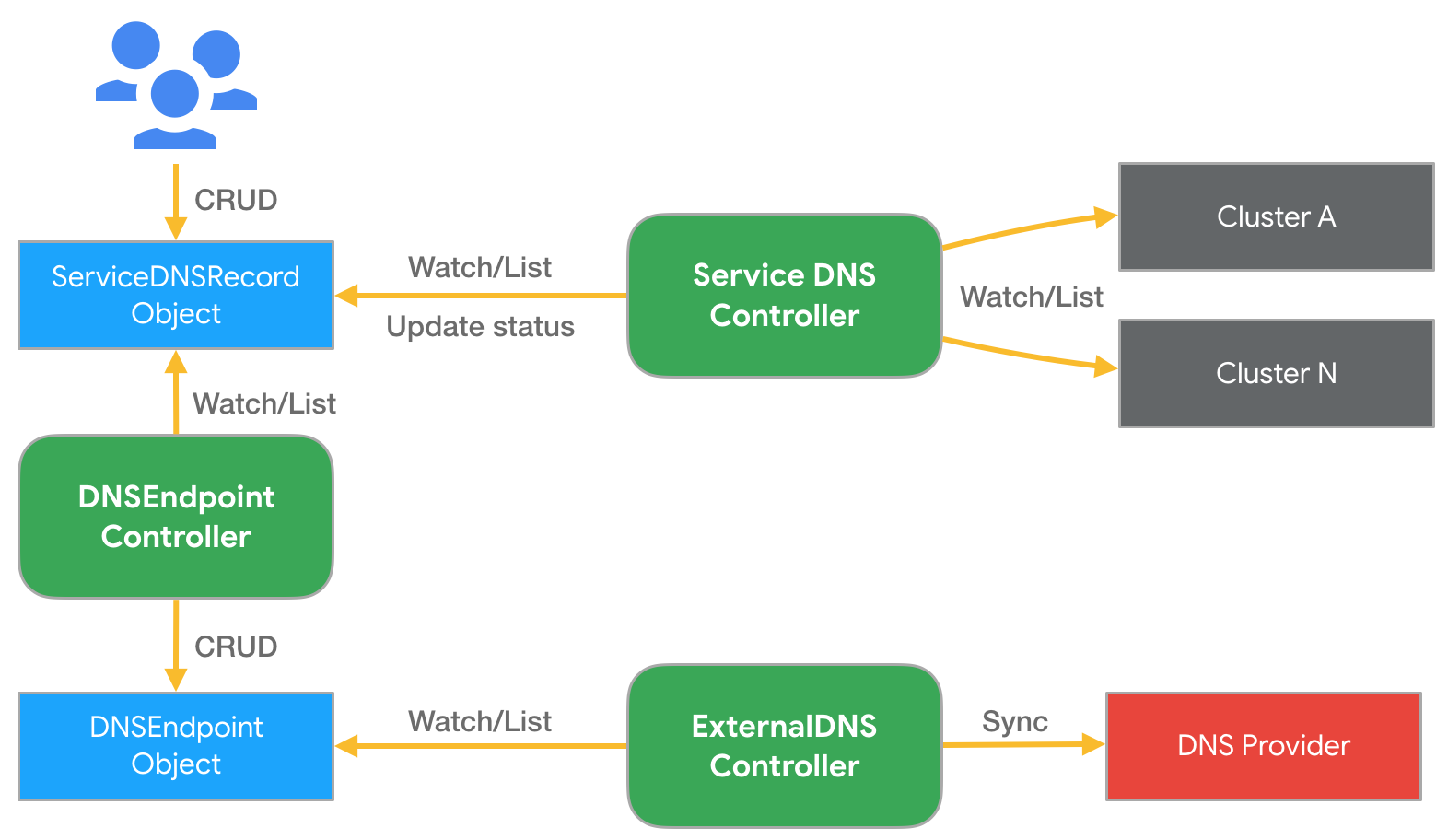
若是 Ingress 的話,會由 IngressDNSRecord 文件取代,並由 Ingress DNS Controller 收集信息。